“搭建系统”的困境和突破
2021-12-31
搭建系统是工具,工具是解决问题的,所以重点关注问题是什么,为什么搭建系统能解决。<br />第二关注工具是怎么解决问题的,解决的结果如何。<br />以及最后的剩下无法解决的问题怎么办?还有办法能解决吗?
基本纲要
- 对齐认知
- 同步“目标”
- 业务
- 技术
- 原子化,沉淀复用
- 原子组件的开发体验要好:少概念,渐进增强
- 同步“搭建系统”的概念,定义,特点
- 同步个人的简单经历
- 代入问题
- 对破局的思考
- 解决方向
- 广度
- 原子化,提升抽象,-> 重新发明html,css,js
- 深度
- 业务
- 需求不可控 -> 需求全部适配 -> 人力填坑 -> 拓展边界 -> 广度问题
- 技术
- 极大增加搭建系统的数量 -> 提升搭建系统的开发效率 -> 搭建系统的搭建系统 -> 搭建系统的基础物料 + 问题域定制
- 换个角度
- 卷往上游,以需求逻辑为中心
- 需求逻辑的描述是必须的,核心的,稳定的
- 需求逻辑是可流程化描述,如流程图
- 基于逻辑是可自动化
- 落地的结局
- 落地的困难
- 和解,放弃完全的NoCode,工程师你回来吧
- 重点解决其中的需求的确定性的部分
- 需求的确定性越高,需求的信息量就越大,编写程序就变得越简单,后续而二次消费也更容易
- 确定边界
- 流程图变成填空题
为什么搭建
C端营销场景:技术服务业务,业务KPI。
- 目标:业务KPI
- 承接:页面
- 目标:快速上线
- 承接:技术
- 目标:页面开发效率 ( 效率 = 工程师 * 页面代码 / 时间)
- 时间不变,提升工程师,提升页面代码
- 目标1:提升工程师
- 目标2:提升页面代码
- 代码不能凭空产生,要么由人(AI)编写,要么使用已经存在的代码
- AI手段:各种 to code,Design to Code, Prd to Code, Flow to Code
- 代码封装,复用
页面搭建系统是符合上述的2个目标的解决方案之一
问题域
搭建工具对应的问题域的特征:
- 技术挑战类:
- 流量大,时效性强
- 状态简单
- 流转关系可以通过逻辑流程图充分描述,并被一般人充分理解
- 状态枚举通常不会超过3个值(如 0/1, 0/pending/1, pending/fulfiled/rejected)
- 业务价值类
- 无序
- 缺少统一标准(技术标准,产品标准)
- 缺少最佳实践,
- 反复验证,AB实验
- 效率优先
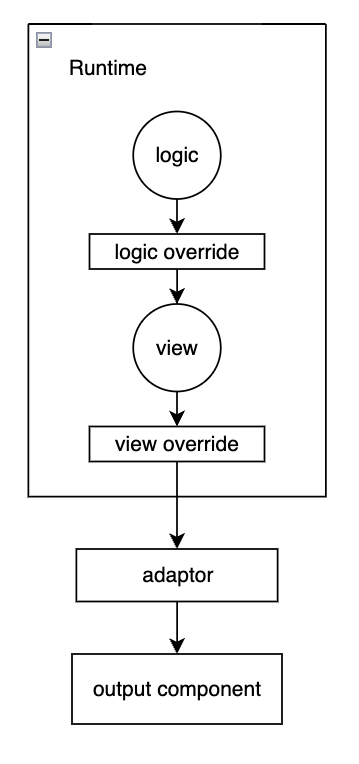
搭建系统最简单实现
基本元素:
page = runtime(json)
假设现在已经用这个公式解决问题了。
这个过程的本质就是一个DSL,所以DSL的局限性也包含了这里说的“搭建系统”的局限性,同时我们狭义的页面搭建系统也有局限性。
2个项目简介
用“搭建”的思路解决问题的过程中,主要做过2个搭建系统,他们除了都叫搭建之外,剩下的技术实现不同,用户不同,解决的问题也不同:
- 电商营销会场H5页面搭建
- 平台用户:
- 技术架构:
- react + jquery
- java模版 + ssr
- 搭建组件 = React组件 + 组件的描述 + 定制编写的编辑区
- 搭建能力:强
- 私有组件标准,组件之间可以嵌套,组合
- 线性布局,绝对定位布局,且能相互组合
- 页面不需要可维护性
- 花呗营销活动H5页面搭建
- 平台用户:
- 技术架构:
- 全栈中中台(react + eggjs + mysql)
- CDN html + 异步接口
- 组件拓展性强
- 搭建模块等价于React组件
- 搭建能力:弱
- 相当于 Array<React.Component> 的一维数组
- 页面不需要可维护性
总结特点:
- 核心目标是:效率
- NoCode
- 不在乎产物的可维护性和可拓展性
可以看到这里做的2个搭建系统他们是相似又不相同:
这么相似能不能在保留核心的特性下只加一点的改造就能互换一下在对方的业务里直接使用呢?不能。因为环境,需求的不同导致了平台之间有显著差异,所以不能。
那有没有可能一个搭建系统就能解决2个业务呢?那肯定能,因为站在现在的视角来看,需求已经确定成产品了,只要再统一一下抽象就行。
合并:提升抽象,提升复杂度
- 搭建能力对齐,都支持多布局
- 组件标准升级,私有标准
- 按业务域划分租户,分隔平台用户
解决之后
往广度思考:<br />一个搭建系统只能解决一个垂直域的问题,如果要跨垂直域,那就意味着要把提升搭建系统的抽象程度,拆解一下把视图结构的用一种DSL,样式的部分用一种DSL,逻辑的部分再用一种DSL 。(黑人问号,重新发明一下html,css,JavaScript ?
往业务的深度思考:<br />除了无法跨域,而且针对搭建系统的上游:需求,逻辑,无法充分收敛。因为上层是完全不可控的,即当技术侧发起的工具/服务无法解决满足上层需求时,就只剩下2个解法:
这2个解法都会出问题
人力填坑相当于开了外挂,一旦开启则无法停下,搭建系统迅速失控名存实亡,沦为鸡肋,其存在的就变成了问题本身。
需求变形,即需求适应系统的短板,站在更上层的视角看,这是对业务的不可避免的伤害。
往技术的深度思考:<br />如果一个搭建无法高效的解决全部问题,那就增多搭建系统的数量,创建能搭建搭建系统的高阶搭建系统,抽象搭建系统本身的组成:输入,中间数据,页面。那么,搭建系统的抽象如何拆解,
搭建系统A -> 问题域X<br />搭建系统B -> 问题域Y
高阶搭建系统X -> A, B -> X, Y
如果:这时候来了新需求Z1,新需求Z1属于问题域Z。(比如:营销人传人)
如果A,B不能满足Z1,解决问题Z,那为什么X能解决问题Z ?可能性🈶2:
- X很先进,提前预判到了Z的存在
- X很灵活,有拓展机制能够让开发者继续开发解决Z
- 本质是劳动力的转移(需要拓展多少?有没有可能是完全重写,那就X不就成了基础框架)
- 问题Z = 新需求Z(1-> Infinity) = ( 新搭建系统 = 高阶搭建系统 + 人力procode )
- 反问:如何衡量ROI,为什么不简化为“人力procode -> 新需求Z0”,
- 反问2:再来个新的W问题如何?上游不可控
如何突破
看流程,视角也许可以从技术侧前移,看看能不能从需求侧解决,俗称:如果解决不了问题,可以尝试换个问题,看看在这整个过程,最核心的点是什么。不是最初的业务目标,而是基于目标描述的业务逻辑。
来自运营的需求目标: 1.提升MAU, 2.有一亿的预算,3.其它指标等<br />产品分析之后并输出之后形成产品PRD:里面描述了产品逻辑,最后开发面对的是这一整套产品逻辑,包含用户,行为,状态事件,最后形成页面。
但是在搭建页面的这些逻辑被分散到各个组件里,经典的场景:在评审需求往往会有一个流程图,但在页面完成后这个流程图就没用了。
再深入一点,充分的把流程图用起来,让静态的流程图动起来。
建设以“逻辑编排”为核心的搭建体系,
以“逻辑”为中心
2个需求示例:日常花呗抽奖活动,花呗五周年小纸条
以流程图为中心,流程图里要包含的基本结构:
- 生命周期上下文
- 基本结构字段
- 人物等客观条件,Value Object
- 计算节点
- 渲染节点
- 渲染
- 等待事件
- 等待渲染的UI 抛出事件(用户行为,自定义描述的事件)
- 拓展信息:
- 逻辑覆盖率
- 监控
- 埋点
- 流量分布
- 自动化压测
- 自动化性能优化
- 业务转化率,漏斗,采集
逻辑怎么不行了
示例1:抽奖
示例2:小纸条翻页
1.是纯前端视角,格局没有打开
2.可覆盖的复杂度不够
“动态 & 前后可翻动的小纸条”让我破了防
NoCode无法覆盖纯逻辑的部分,但是NoCode依然保留有能力无限且复杂的逻辑确定下来。
对业务来说可以是一个黑盒,黑盒只暴露接口,“动态 & 无限可翻动的小纸条”有2个接口:翻页完成,翻页退出,借助Code的手段从而完成降维
和解,放弃完全的NoCode,重点解决其中的需求逻辑的确定性的部分
需求逻辑的确定性越高,需求逻辑的信息量就越大,编写程序就变得越简单,后续而二次消费也更容易,流程图变成填空题
3.无法很好的处理循环和循环退出<br />拓展一下,即语义的逻辑和实际的程序逻辑不是一一一对应的,中间是有抽象的,如:
点击tab offset=0 -> getList
点击pagination offset+=1 -> getList
程序:任意点击行为,offset changed -> getList(offset)
而且语义的逻辑经常会默认带一下脑内上下文,比如点击tab,默认就清空了前面的变量,或者意识人,非技术人员通常会分别 每个tab都是独立的逻辑,而程序逻辑则可能是为了性能,默认复用变量
逻辑的边界
当我意识到在逻辑上的产品经理(或需求方)不应该去关注如何底层的程序细节时,同时让产品描述逻辑是可行的,那就说明在这个产品 -> 逻辑的路径上存在一个边界。
最先开始:产品 -> 需求 -> 工程师 -> 逻辑
原本的设计:产品经理 -> 逻辑(这里的逻辑即包含了业务逻辑和程序逻辑,同时工程师参与但也负责逻辑的正确性,完备性,逻辑有问题就如同需求有问题,如同程序出了bug)
业务逻辑一定包含程序逻辑,但反过来程序逻辑不一定是业务逻辑。(参照声明式编程和指令式)
转账 = move(A.balance,B.balance)
借钱 = move(A.balance,B.balance)
加入工程师之后的设计:产品经理 -> 业务逻辑(声明式,关心用户,UI,业务状态) -> 工程师 -> 程序逻辑(类库或接口, 复用或者新开发,按业务逻辑进行填空,关心数据,稳定性)
当考虑到工程师角色参与之后,我意识到这个“边界”不是一个确定性静态的值,它应该是工程师和产品在认知上达成的统一共识,而且会随着产品不停迭代动态变化。“边界”的作用不再是对立性的,而是为了寻求最佳的解法。
再进一步抽象一下:
产品 -> 结构化后的需求 -> 工程师 -> 代码
结局
一个瑕疵明显的NoCode方案,不容易打动人心,落地阻力大。
人们工程师们对于NoCode和ProCode有很高的质疑,但对于lowCode则很包容
- no code表面太完美,工程师天然直觉认为必定非code不可解决的地方,这将来是一个深坑
- pro code本就是工程师的专业领域,这是专业领域的碰撞,语言只有2种被人喷的和没人用的
- low code 则取决于视角和比例
- 观点1:low的部分是帮助工程师减轻负担
- 观点2:code的部分是增加了工程师的负担